首先让我们思考一下,如果现在产品需要在页面上提供富文本编辑器应该怎么实现🤔
一般来说方式有以下几种。
- 我们可能会想到借助一些编辑器框架、编辑器组件。比如说是ueditor、tinyMCE、draftjs等等。
- 或者,我是一个造轮子资深爱好者,决定自己实现。通过使用HTML自带的属性contenteditable。
没错,现在市面上流行编辑器的也可以分为这两个种类。
当然如果你只是想实现一些简单的功能。比如像有人一样,通过@去metion一个用户,通过#加上日志的类型。
那么也可以使用textarea,然后通过绝对定位去处理文本的高亮,以及待选列表的展示等等。
但是这也随之带来了一些问题。
比如在Facebook2016年介绍Draftjs的演讲里,他说Facebook早期也是通过这种方式去metion一个人的。
首先textarea自带一些小问题——不会随着输入而增高等等。
但是他们发现就有无法正确定位的bug,redo、undo、复制黏贴破坏了metion。
https://signavio.github.io/react-mentions/master/ 可以看一下React-Metion的这个demo,当我们去破坏metion的时候,这个体验就变得不符合预期了
好,我们现在来介绍一些现在主流的几种编辑器的实现。
一种,就是基于HTML的contenteditable实现。
比如说我们刚才提到的ueditor、tinyMCE。
这个属性兼容性非常优秀。没记错的话从IE5开始浏览器就支持这个属性。它允许用户在普通标签里面编辑富文本的内容。同时还有document.execCommand这个更加优秀的API,可以支持格式化文本。后面还新增了比如events、caret、plaintext-only这样的属性,让你控制编辑器只能输入纯文本等等。 https://w3c.github.io/editing/contentEditable.html#contenteditable
不过经过广大开发者多年的实践。我们很难说这个contenteditable是好还是坏。 因为这个坑爹属性在不同浏览器下表现不一致。一个回车,可能出现一个<p>,可能是<div>,也有可能是<br>。
https://www.oschina.net/translate/why-contenteditable-is-terrible?cmp https://medium.com/content-uneditable/contenteditable-the-good-the-bad-and-the-ugly-261a38555e9c
这导致你没有办法把视图抽象成一个模型。另外存储数据的时候也是,因为没有办法抽象,你在存储数据的时候就需要存储一段HTML。之后你可能又要花很多精力去处理安全问题。
现在我们在做IM的时候就遇到这样的问题,业务爸爸们想要富文本,但是DBA不同意啊,这个字段太长啦!不存不存我们不存!
OK,假如我们的字段够长,DBA同意你存储HTML string。现在想想如果我们想要他输入的内容符合我们的预期行为该怎么办。比如我们回车就是要p标签。第一个想到的可能是监听onKeyPress事件,如果有回车,就手工插入一个p。https://codepen.io/eleanormao/pen/QJezvG 然后坑爹了。redo和undo事件被破坏了。
这个问题在有道云笔记的分享里面也有提到。https://sq.163yun.com/blog/article/168068797113712640 使用document.execCommand对内容修改时,浏览器内部会对该contenteditable区域维护一个undo/redo栈,使得每一个修改行为可以撤销和重做。如果一旦使用了document.execCommand之外的DOM API修改内容,就会破坏undo/redo栈的连续性,导致撤销和重做出错或失效。
然后你又需要花费很多事件去处理这个问题。另外因为每个浏览器中行为都不一样,你可能在chrome里面实现了,但在火狐里面就有bug了。之后你可能就因为把项目延期了几个月被公司优化掉了。
当然contenteditable的开发者做了很多的努力,所以上述的这些优秀的插件,帮我们解决了这些问题。
但是不得不说如果有朝一日产品需要协同编辑,或者自定义一些类型的节点,那可能又要遭遇天坑了。
还有作为一个React开发者,我们会发现它不React。因为DOM===State。
第二种,就是超越了contenteditable。
利用了contenteditable,但是不依赖contenteditable。它们在内部自定义一套数据模型,与视图对应。做到了数据与视图的分离。让contenteditable变得可控。
这样类型的编辑器,通常可以通过传入一个schema去做一个定制内容,还有因为他变得可控,解决了contenteditable编辑器不能协同编辑、很难自定义的问题。
另外因为他其实维护的不是DOM本身,而是一组数据,所以序列化Markdown、存储数据的都变得简单。
这里我主要介绍Slate。
它和Draft.js一样,他不能开箱即用,不是一个应用。他是一个可完全定制化的富文本编辑器框架。可以把它看做是一个基于React和Immutable的,可插拔的contenteditable。 它利用了React,不需要再去重新构建一套视图的轮子。利用Immutable实现了不可变的数据模型,这点和Draft.js一样。
这里介绍一些Slate的几个原则。
- 插件是一等公民。它的所有逻辑,都是通过一系列的plugins完成。甚至它的核心代码其实也是一个plugin。它把一系列插件的List叫做插件栈。和express和koa的中间件比较类似。当处理事件和富文本的时候它会依次通过插件去处理请求。
- scheme-less的内核。Slate 的核心逻辑并不对你所编辑的数据结构做任何假设,这意味着你在需要应对复杂场景时不会被编辑器预置的内容所束缚
- 嵌套文档模型。一个前端工程师不可能不熟悉DOM结构,所以它设计时,也把数据结构竟可能的镜像DOM结构。 比如document下面是block,还有inline、text、range、selection。很好理解,降低了学习成本。同时嵌套的递归的结构,也可以很好的支持复杂的DOM结构。 比如说表格之类的。还有我们知道自由都是建立在规则的基础上的嘛,所以Slate也为数据结构定义了一些强制性的规则。比如说不能有相邻的Text节点、inline节点下面不能有block节点等等。当你改变内容的时候还会自动强制执行normalizer,使数据结构吻合预期。
- 与DOM平行。数据模型是建立在DOM基础上的,即,文档是一个嵌套的树。有selection和ranges。并且暴露了所有标准的事件handlers。这使插入例如表格和引用变得可能。任何你在DOM里面能做的,都可以在Slate里面实现。
- 无状态的view和不可变的数据。通过React和Immutable.js。Slate编辑器使用构建了一个无状态的、数据不可变的编辑器。
- 直观的变更。这里也可以看到Slate是一个十分注重API表现力的框架。他把所有对富文本的操作都变成对editor对象的命令。并且所有的操作都是链式的。

- 可协同编辑的数据模型。
- 消除了内核边界。因为用了好多插件~
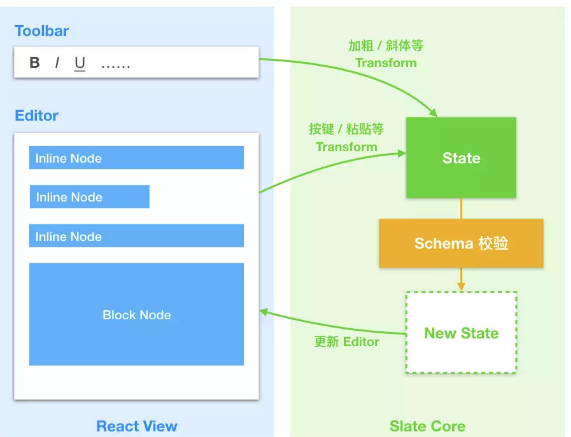
我们可以发现,有了M,有了V,其实Slate就是一个C。在看他源码的时候也可以发现他的代码分别放在models、controller文件夹下面。
Slate提供了React组件slate-react,他暴露出一个Editor组件,不过这个组件其实是他controller editor.js的实例。传入的属性(比如onKeyDown、Schema、巴拉巴拉)其实也是一系列插件,Editor实际上是用来管理这些插件的。
盗一张图来描述一下Slate的数据流动。讲一下他是专门做到视图的统一的。 他的onChange事件其实是滞后的、异步的,其实改变已经反映在视图上了,然后再传递给的onChange。